ChatLearn: A flexible and efficient reinforcement learning framework for large language models(LLMs)¶
Introduction¶
ChatLearn is a large-scale reinforcement learning training framework for LLMs developed by the Alibaba Cloud PAI platform.
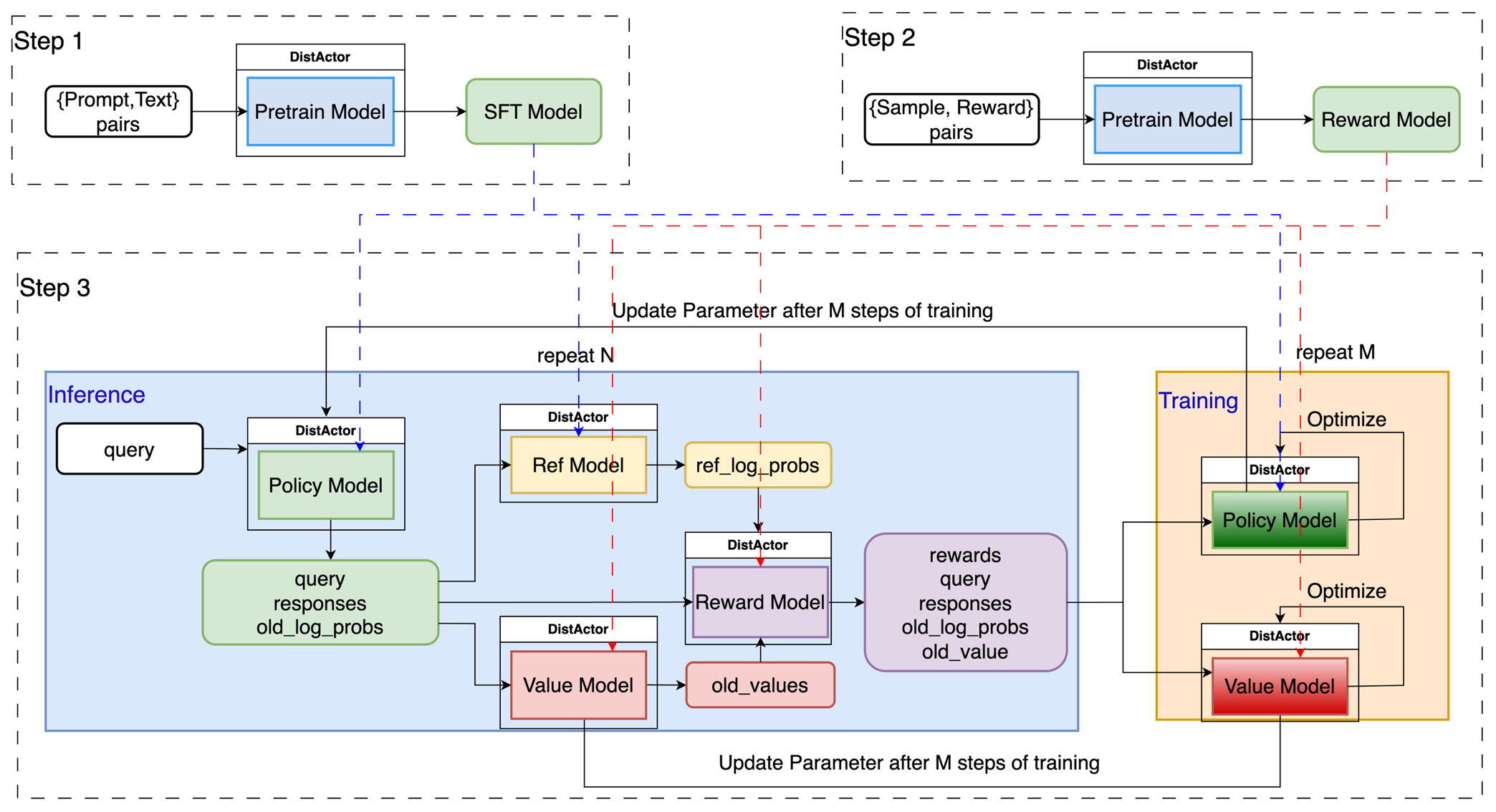
Chatlearn has the following advantages:
🚀User-friendly programming interface: Users can focus on programming individual models by wrapping a few functions, while the system takes care of resource scheduling, data and control flow transmission, and distributed execution.
🔧Highly Scalable Training Methodology: ChatLearn supports user-defined model execution flows, making customized training processes more flexible and convenient.
🔄Diverse Distributed Acceleration Engines: ChatLearn supports industry-leading SOTA training (FSDP2, Megatron) and inference engines (vLLM, SGLang), delivering exceptional training throughput performance.
🎯Flexible Parallel Strategies and Resource Allocation: ChatLearn supports different parallel strategies for various model configurations, enabling the formulation of distinct parallel approaches tailored to each model’s computational, memory, and communication characteristics. Additionally, ChatLearn features a flexible resource scheduling mechanism that accommodates exclusive or shared use of resources across models. Through its system scheduling policies, it facilitates efficient serial/parallel execution and optimized GPU memory sharing, enhancing overall performance and efficiency.
⚡High performance: Compared to current SOTA systems, ChatLearn achieves a 52% performance improvement at the 7B+7B (Policy+Reward) scale and a 137% performance improvement at the 70B+70B scale. Meanwhile, ChatLearn supports reinforcement learning training at scales exceeding 600B parameters.
Quick Start¶
Please refer to the documentation for a quick start.
Feature List¶
Supports inference engines including vLLM and SGLang, controlled via the
runtime_args.rollout_engineparameterSupports reinforcement learning algorithms such as GRPO and GSPO
Supports experiment monitoring with wandb and tensorboard
Supports training acceleration techniques such as sequence packing, Ulysses sequence parallelism, and Group GEMM
Performance¶
We compared the RLHF training throughput of models with different parameter scales, adopting an N+N model configuration where both the Policy model and the Reward model have the same number of parameters. We benchmarked against DeepSpeed-Chat and OpenRLHF with 7B and 70B model configurations. For the 8 GPU setup with a 7B+7B scale, we achieved a 115% speedup; for the 32 GPU setup with a 70B+70B scale, the speedup was 208%. The larger the scale, the more pronounced the acceleration effect becomes. Additionally, ChatLearn can support even larger-scale reinforcement learning, such as at a 600B scale.
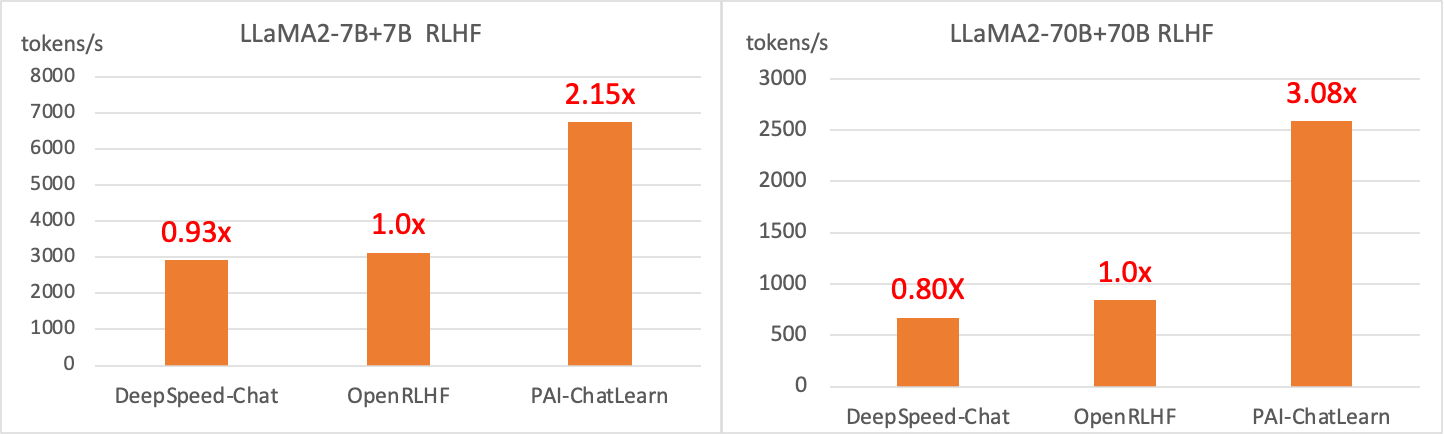
Note: The performance of DeepSpeed-Chat and OpenRLHF has already been optimized.
Roadmap¶
The upcoming features for ChatLearn include:
- Simplify Configuration Settings
- Support tutorials for the RL training of MoE (Mixture of Experts) models
- Support for more models
- Performance Optimization
- Support for more RL algorithms